Google Introduces T5Gemma 2: Encoder Decoder Models with Multimodal Inputs via SigLIP and 128K Context
Google has released T5Gemma 2, a family of open encoder-decoder Transformer checkpoints built by adapting Gemma 3 pretrained weights into an encoder-decoder layout, then continuing pretraining with the UL2 objective. The release is pretrained only, intended for developers to post-train for specific tasks, and Google explicitly notes it is not releasing post-trained or IT checkpoints for this drop.
T5Gemma 2 is positioned as an encoder-decoder counterpart to Gemma 3 that keeps the same low level building blocks, then adds 2 structural changes aimed at small model efficiency. The models inherit Gemma 3 features that matter for deployment, notably multimodality, long context up to 128K tokens, and broad multilingual coverage, with the blog stating over 140 languages.
What Google actually released?
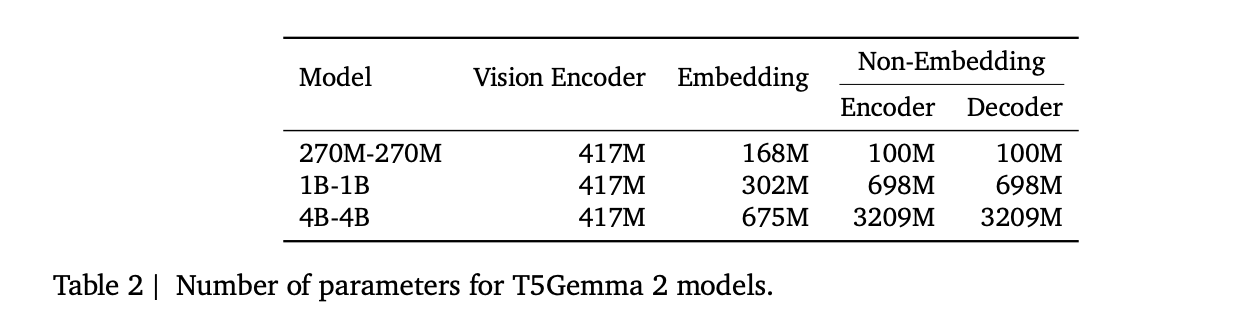
The release includes 3 pretrained sizes, 270M-270M, 1B-1B, and 4B-4B, where the notation means the encoder and decoder are the same size. The research team reports approximate totals excluding the vision encoder, about 370M, 1.7B, and 7B parameters. The multimodal accounting lists a 417M parameter vision encoder, along with encoder and decoder parameters broken into embedding and non embedding components.
The adaptation, encoder-decoder without training from scratch
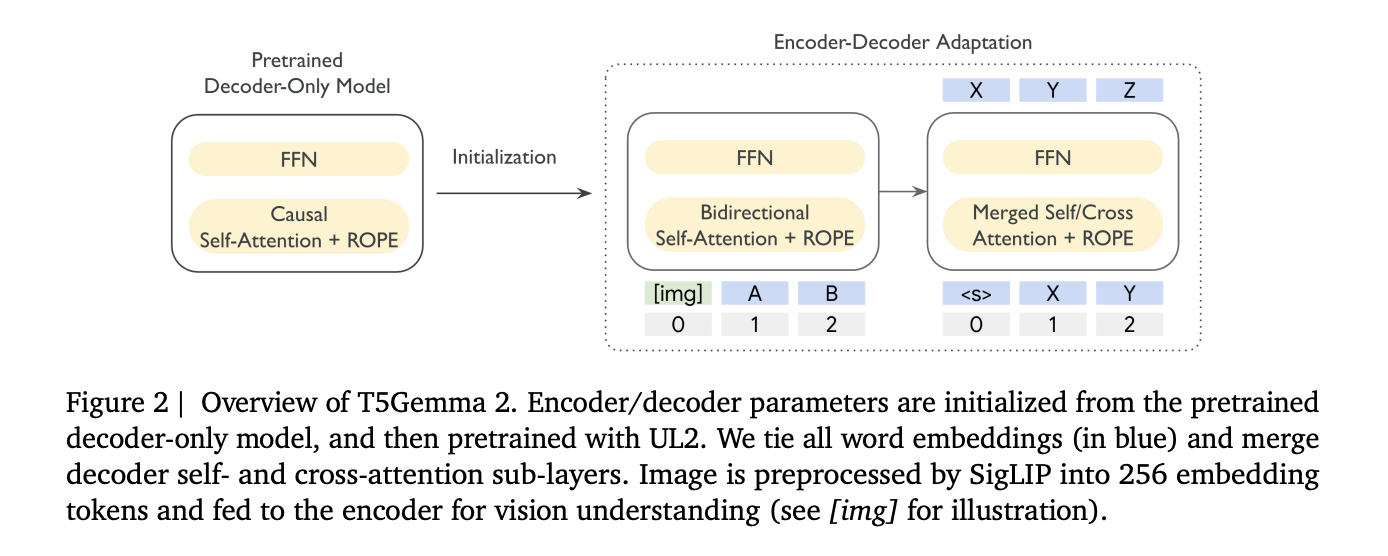
T5Gemma 2 follows the same adaptation idea introduced in T5Gemma, initialize an encoder-decoder model from a decoder-only checkpoint, then adapt with UL2. In the above figure the research team show encoder and decoder parameters initialized from the pretrained decoder-only model, then pretrained with UL2, with images first converted by SigLIP into 256 tokens.
This matters because encoder-decoder splits the workload, the encoder can read the full input bidirectionally, while the decoder focuses on autoregressive generation. The research team argues this separation can help long context tasks where the model must retrieve relevant evidence from a large input before generating.
Two efficiency changes that are easy to miss but affect small models
First, T5Gemma 2 uses tied word embeddings across encoder input embedding, decoder input embedding, and decoder output or softmax embedding. This reduces parameter redundancy, and references an ablation showing little quality change while reducing embedding parameters.
Second, it introduces merged attention in the decoder. Instead of separate self-attention and cross-attention sublayers, the decoder performs a single attention operation where K and V are formed by concatenating encoder outputs and decoder states, and masking preserves causal visibility for decoder tokens. This ties to easier initialization, because it narrows differences between the adapted decoder and the original Gemma style decoder stack, and it reports parameter savings with a small average quality drop in their ablations.

Multimodality, image understanding is encoder side, not decoder side
T5Gemma 2 is multimodal by reusing Gemma 3’s vision encoder and keeping it frozen during training. Vision tokens are always fed to the encoder and encoder tokens have full visibility to each other in self attention. This is a pragmatic encoder-decoder design, the encoder fuses image tokens with text tokens into contextual representations, and the decoder can then attend to those representations while generating text.
On the tooling side, T5Gemma 2 is placed under an image-text-to-text pipeline, which matches the research’s design, image in, text prompt in, text out. That pipeline example is the fastest way to validate the end to end multimodal path, including dtype choices like bfloat16 and automatic device mapping.
Long context to 128K, what enables it
Google researchers attributes the 128K context window to Gemma 3’s alternating local and global attention mechanism. The Gemma 3 team describes a repeating 5 to 1 pattern, 5 local sliding window attention layers followed by 1 global attention layer, with a local window size of 1024. This design reduces KV cache growth relative to making every layer global, which is one reason long context becomes feasible at smaller footprints.
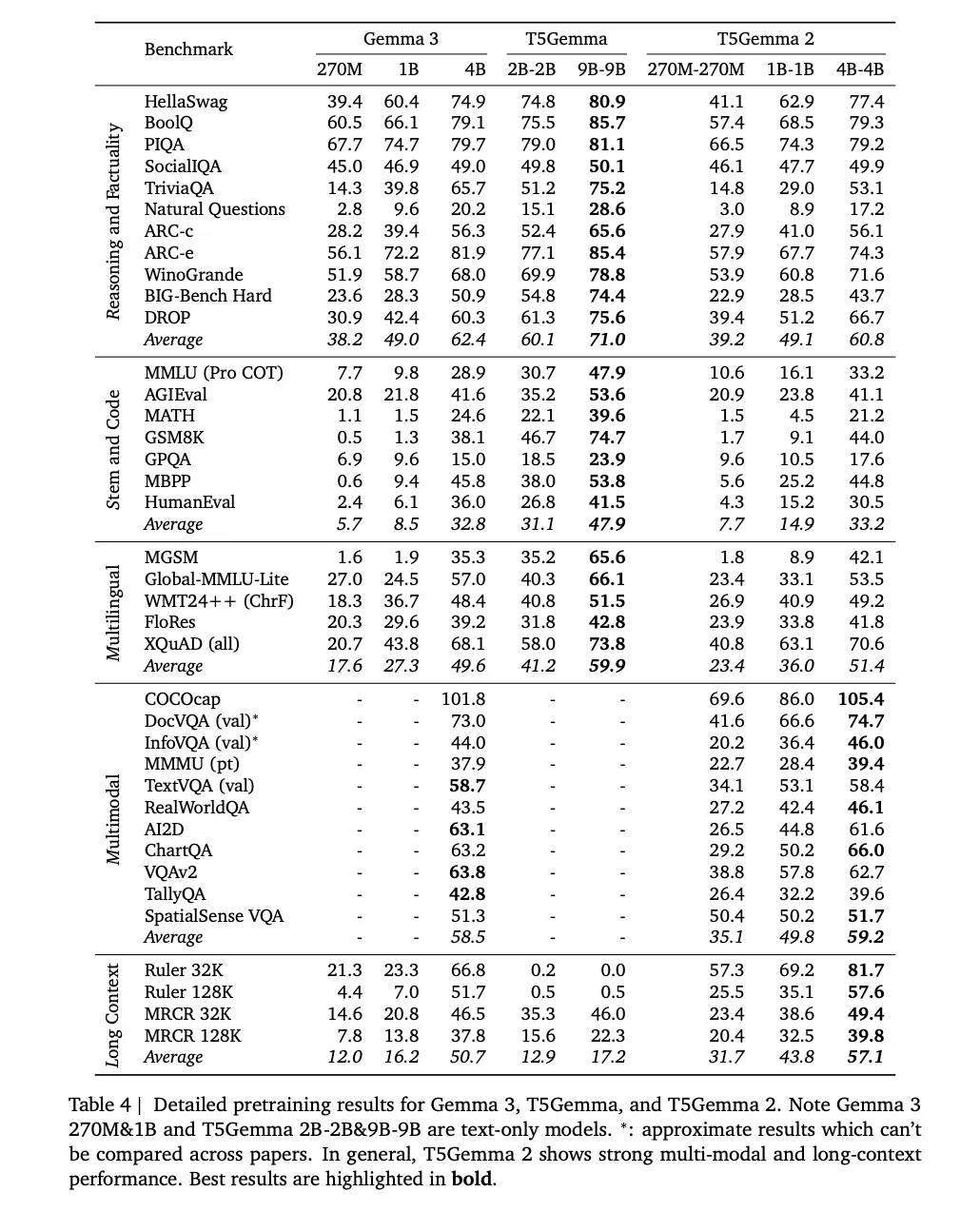
In the T5Gemma 2, the research team also mention adopting positional interpolation methods for long context, and they pretrain on sequences up to 16K input paired with 16K target outputs, then evaluate long context performance up to 128K on benchmarks including RULER and MRCR. The detailed pretraining results table includes 32K and 128K evaluations, showing the long context deltas they claim over Gemma 3 at the same scale.
Training setup and what “pretrained only” implies for users
The research team states the models are pretrained on 2T tokens and describes a training setup that includes a batch size of 4.2M tokens, cosine learning rate decay with 100 warmup steps, global gradient clipping at 1.0, and checkpoint averaging over the last 5 checkpoints.
Key Takeaways
- T5Gemma 2 is an encoder decoder family adapted from Gemma 3 and continued with UL2, it reuses Gemma 3 pretrained weights, then applies the same UL2 based adaptation recipe used in T5Gemma.
- Google released pretrained checkpoints only, no post trained or instruction tuned variants are included in this drop, so downstream use requires your own post training and evaluation.
- Multimodal input is handled by a SigLIP vision encoder that outputs 256 image tokens and stays frozen, those vision tokens go into the encoder, the decoder generates text.
- Two parameter efficiency changes are central, tied word embeddings share encoder, decoder, and output embeddings, merged attention unifies decoder self attention and cross attention into a single module.
- Long context up to 128K is enabled by Gemma 3’s interleaved attention design, a repeating 5 local sliding window layers with window size 1024 followed by 1 global layer, and T5Gemma 2 inherits this mechanism.
Check out the Paper, Technical details and Model on Hugging Face. Also, feel free to follow us on Twitter and don’t forget to join our 100k+ ML SubReddit and Subscribe to our Newsletter. Wait! are you on telegram? now you can join us on telegram as well.
The post Google Introduces T5Gemma 2: Encoder Decoder Models with Multimodal Inputs via SigLIP and 128K Context appeared first on MarkTechPost.